Summary
This is a recap of a recent project I did where a client with several thousand customer and directory websites and several thousand specific local and national search keywords needed to process all that information into SEO-optimized locality-specific URLs. The project resulted in over 60,000,000 URLs being processed nightly and adding these URLs to over 3,000,000 virtual search-specific pages. The challenge here was the sheer amount of data to be processed quickly enough so that every morning up-to-date URLs would be on all client customer’s online properties.
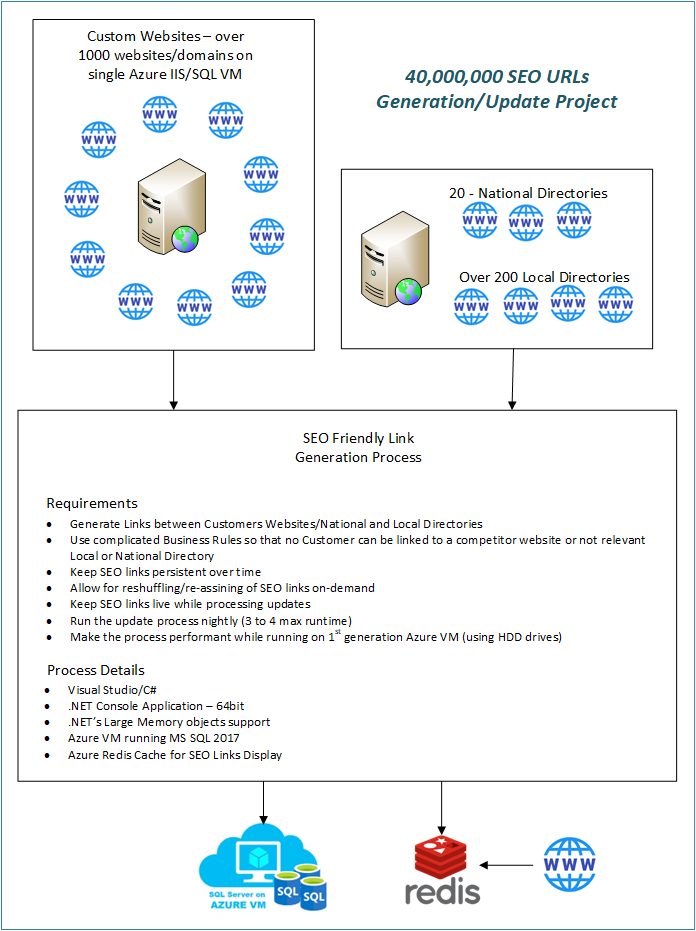
Project Details
Here’s what I needed to do.
- The client has thousands of websites
- The client also has some Local and National Directories
- Client several thousand SEO-friendly search keywords.
The client wanted to have specific SEO-friendly URLs linking all of his online properties. My job was to use all these data to generate links to and from all his online properties with very specific business rules; none of the client’s customers can be linked to one another, but customers can be linked from directories, customers can only show up on local directories within a certain distance to make the local searches relevant, there can be no duplicate links (both source and target) on the same page, some customers would choose to opt out of the links, etc. There are a lot more very specific business rules.
Rules aside, the list of customers is dynamic, more customers sign up, some quit, some change their address, domain, etc. So the engine that generates all these links has to be dynamic and run nightly – this means it has to be finished within a few hours. So with these requirements, I had set up to design the application – a .NET Console application that would be triggered as a scheduled task every night.
First I wrote the business end of things – all the business rules about generating the links. After some tweaks, the engine was done and when it was completed I was getting about 60 million links. This means over 60 million records in a single SQL table. At first, I was simply working on the data/links generation and not persisting the data to the database. the first time I added the database into the mix, kick-started the process, and waited an hour or so to complete the database imports. To my surprise after a couple of hours the process was still going, OK – waited a little longer same thing.
Pretty soon I realized something was off about my time assumptions, had to stop everything and instrument the process to get back the performance and completion matrix to see how things were going. Well, turns out that with just my original one-record-at-a-time procedure it would have taken about a month to the entire process to complete. Ouch, not acceptable for a process that needs to run and complete overnight.
I had to seriously think about the performance with the SQL server in mind, generating the data means nothing if it takes too long to save or retrieve it. I had to do serious research about how MS-SQL server deals with data IO. My first pass was using Entity Framework for records-by-record inserts, updates, and deletes – that didn’t work, it would have taken over a month to complete. Then I tried to use dynamic SQL with each statement batch inserting 1000 records – with this approach, I run into SQL Command Batch size limit first. Once I got my SQL Insert command under the batch size limit I was able to quickly insert the first 1000 records. So, I kick-started the process of inserting all 60,000,000 records using this approach. Again it was taking too long. But this time I did the math, inserting the 1000 records was taking less than a second, so it should have taken only a few hours. Checking the progress on the server side, I soon realized I couldn’t even check the row count – SELECT COUNT(*) FROM dbo.TableName was not returning anything.
Back to the drawing board and instrumenting the new process. Turns out the 1st 1000 records go in very quickly – less than a second, then the 2nd 1000 records take about 2 seconds, the 3rd chunk of data takes over 8 seconds, and the 4th 1000 records was taking over the minute – see a pattern here? It was the indexing that was so drastically slowing things down, pausing the insert to let the index build from the previous insert. Again a roadblock – need a different approach.
After a few more designs and quick prototypes, I have finally settled on a design. I needed to use the .NET SqlBulkCopy class for fast imports. I had to make my console 64bit only Application and enable .NET’s Large Memory objects support to allow in-memory HashSet (like a List/Array but optimized for searches) objects. So here’s what the process looked like:
- Put all Customer Local and National Directories and other relevant data into HashSets
- Use Customer’s and Directories dataset boundaries to break the entire processing into several passes.
- Each pass would generate about 5-10 million links
- Use .NET SqlBulkCopy to insert these 5-10 million links into SQL
This process worked. The memory footprint of the running process was about 8GB and the whole thing was taking about 3 hours to complete. Success – right?
Not so fast – I have to run this process every night. The first time around it’s all about SQL inserts, then after that it’s all about inserts/updates and deletes. Again back to making design changes to get the consecutive process runs under the 1-2 hours threshold. I had already figured out how to use the bulk imports, so inserts were not an issue anymore. Deletes on the other hand were a problem, deleting a lot of records, sometimes over 100 or 300 thousand records was taking too long; the SQL was pausing the next deletes to let the index update for the previous deletes. Keep in mind taking out indexes was not an option – searching the data would have taken too long. So, more thinking and testing. In the end here is the updated process:
- Process the entire dataset (dataset for each customer/directories pass) and generate the list of Inserts – then insert them with .NET SqlBulkCopy
- Process the same dataset and determine what needs to be deleted.
- For the data to be deleted – build an in-memory table with one column – the ID of the record to be deleted.
- Issue SQL Delete command using WHERE IN() – IN selects the IDs from the in-memory SQL table
- This would delete all records to be deleted
- Then I drop the in-memory table and move on to processing the next dataset
- While I was processing the next dataset in C# for all the appropriate business rules the SQL server had a chance to update the index and be ready for the next insert or delete.
Great – all that worked. Now onto how to display the chosen (persistently chosen) 8 links on a specific page. Selecting 8 records out of 60,000,000 records per page view was not an option, putting too high of a load on the SQL server. Enter Azure Redis Cache – Did I mention that this process had to run and run well on Azure VM with SQL Server installed? At the time Azure VMs only had regular hard drives, not SSDs, and performance was much slower than is available right now.
So the final piece of the puzzle was pre-processing all 60,000,000 links into Azure Redis Cache, each set of 8 links would get a key specific to a web page. At run-rime pages would have nothing to do with SQL, they just ask Azure Redis Cache if the Key is in the Cache and if yes, they get it, de-serialize it into a list of links, and display it on the page.
I was pretty pleased with the result, the whole process now takes about 1-2 hours to run, and while it’s running since there is no direct link to customers/directories websites, only after the process pushes the updates to Azure Redis Cache then changes become visible. This ended my saga of nightly processing of over 60,000,000 SEO Links in SQL server with .NET and C#.
Please let me know if you have any questions or comments.
Sincerely,
Vardan Mkrtchyan
The Developer Guy.